2026春 2025春 课程号:CS402801
- 课程难度:中等
- 作业多少:很多
- 给分好坏:一般
- 收获大小:一般
| 选课类别:计划内与自由选修 | 教学类型:理论实验课 |
| 课程类别:本科计划内课程 | 开课单位:计算机科学与技术系 |
| 课程层次:专业选修 | 学分:3.0 |
本课程是计算机科学与技术学院本科生专业选修课程。主要目的是让学生掌握深度学习的基础知识、掌握应用深度学习解决实际应用问题的方法。
本课程主要讨论深度学习算法及其在计算机视觉、自然语言处理、图分析挖掘、推荐系统中的应用。具体内容包括: 深度学习的基本概念、深度卷积网络、循环神经网络、Transformer、Diffusion生成模型、大语言模型、思维链与上下文学习等。该课程将理论和实践紧密结合,在夯实学生的理论分析能力同时,锻炼学生的动手实践能力。
教学内容与质量
《深度学习原理与实践》课程涵盖计算机视觉(CV)和自然语言处理(NLP)的经典场景,实验采用具有工程性但有人认为是"玩具"的RAG系统。授课内容与实验关联不大,但质量较高。课程设计实验为主,课程实际内容简单明了,适合想获得学分的学生。
实验与项目要求
课程包含四个主要实验,分别涉及CNN图像分类、BERT文本分类、RAG系统设计和Kaggle竞赛。实验被认为“老套”,工作量大,尤其是实验三存在下载和测试复杂的问题。实验给的时间较长,但文档简陋、要求多且不够清晰。
考核与评分
课程无考试,实验占主要评分部分。有频繁的小测,每次一分。给分引发争议,有人认为“不建议选课;有这时间不如睡觉💤”,给分偏低且缺乏反馈,选修课没有考试但实验量大。
建议与改进
建议优化实验安排、减少下载要求,并简化测试步骤。总体来看,实验需要更合理的设计和反馈,以提高学生的实际收获。
- 课程难度:中等
- 作业多少:很多
- 给分好坏:超好
- 收获大小:很多
- 难度:中等
- 作业:很多
- 给分:超好
- 收获:很多
出分了回来补个评课,下面贴个仓库,欢迎来star(但是注意不要照抄,本实验严查抄袭)。
https://github.com/magichear/Machine_Learning
个人情况:在大三春季学期之前几乎完全不会深度/机器学习相关(人工智能基础67,srs这门课屑中屑),大三春选修了《深度学习实践》(30分大作业完全没做,70)、《深度学习导论》(没出,目前bb总分317.4/350)、《深度学习原理与实践》(93)、《人工智能安全》(90)
这门课的情况跟评课社区其他同学说的一样,覆盖了CV、CL的两个经典场景,并配上了一个具有一定工程性的RAG系统(虽然我实习面试的时候被对面说这是玩具)。整体课程以实验为主,授课内容与实验的相关性不大,课堂小测全开卷而且并不是很复杂(意思是你可以快速扫描题目喂给AI),实验全都非常经典且在领域内较有代表性
因此
- 如果你只想拿到这个学分,上课去了就行了,实验全部做完,拿个保底3.3+应该没什么问题
- 只要从拓展内容里抽两个相对简单些的来做就可以拿到很高的保底
- 准确率之类指标可能只看第一个实验(因为后面的都不太好量化评估),因此第一个实验准确率最好是要弄好(参考:我的CIFAR-10准确率91%)
- 如果你想有所提高,其实也可以听一听老师讲的课,内容质量上还是比较不错的
- 还可以再去选一个深度学习实践(这个就完全不用听课,认真做实验即可,对入门选手(非python小白)收获很大)

本课程需要优化的一点主要就是实验的安排,lab3和竞赛集中在期末月,时间极其紧凑(以至于我直接开摆,不搞深度学习实践的大作业了;这门课的竞赛最后也是摸鱼划水过,打了connectX,稳定在50-60)

本课程美中不足之处就在Lab3:首先是数据源的下载,我相信班里绝绝大部分同学应该是没有这个下载能力的(在课上还能听到老师说部分同学前面实验的模型都不好炼);此外,实验的测试部分极其 dirty ,感觉像找了个100块一天的实习工作专门干 dirty work,自己准备50组测试prompt并分析(我还搞了个全流程半自动化,不然更dirty),整合之后的实验报告有60页A3,我保证这是我那个月里最折磨的几天。
建议:在瑞克网上提供一组完整的PDF数据(元数据可以不打包,让同学自己去kaggle下载筛选);测试要求可以稍微简化一下,现在的太太太 dirty 了
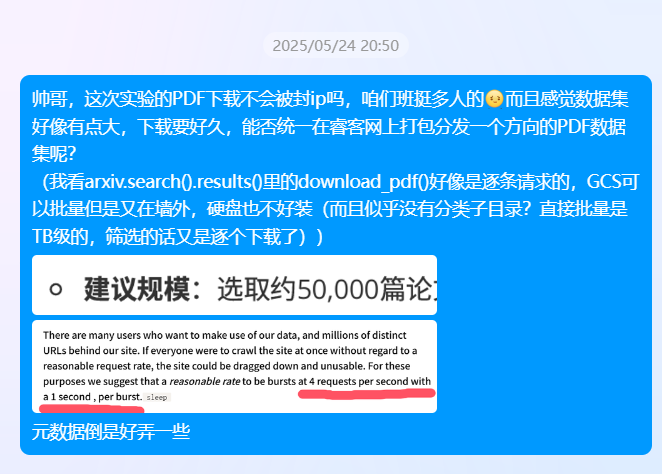

最后也是成功劝阻助教将PDF原文解析改成了选做2333
- 课程难度:中等
- 作业多少:很多
- 给分好坏:一般
- 收获大小:一般
- 难度:中等
- 作业:很多
- 给分:一般
- 收获:一般
优点:
没作业没考试,实验周期长
缺点:
小测多
实验很抽象,我不理解为什么你两个附加要占那么多分,那我问你,附加的意义是什么
实验像极了甲方不停加需求时候的嘴脸
课上卷怪横生,全是卷逼
实验时间普遍出现在很靠近学期后半段,一边准备夏令营一边实验很破防
给分感觉很垃圾,又被卡计了
总结:
这是一门不建议选的课,有这时间不如睡觉💤
- 课程难度:中等
- 作业多少:很多
- 给分好坏:一般
- 收获大小:一般
- 难度:中等
- 作业:很多
- 给分:一般
- 收获:一般
优点:给算力、课程内容简洁明了
缺点:实验量大,实验报告内容要求多,描述不够清晰
其他信息:应该是有5次小测/点名一次1分,实验从放出到截止有1个月,延迟一周以内提交60%分数,共3次普通实验和一次综合实验
我觉得实际我会打7分吧,只是现在的1分还是太夸张了,多打一分
注:考虑到这是3学分无考试的专业选修,实验量大其实无可厚非,最大的问题是实验要求比较粗糙
- 课程难度:中等
- 作业多少:中等
- 给分好坏:杀手
- 收获大小:没有
- 难度:中等
- 作业:中等
- 给分:杀手
- 收获:没有
中规中矩的课,没学到什么东西,给分我个人感觉也比较一般
主要是4个实验:
实验一:基于CNN的CIFAR-10图像分类
实验⼆:基于 BERT 的⽂本分类实验
实验三:基于arXiv学术论⽂知识库的RAG系统设计
综合实验:选一个kaggle比赛
实验文档写的比较简陋,实验内容也有点老套了,相似的内容可能在别的课都做过了,收获不大.
而且实验工作量有点大,感觉设计的不是很合理
提一下实验三,一开始似乎是希望下载50,000篇arxiv的论文,然后解析pdf做成RAG ( 设计的时候真的自己做过一遍了吗 ). 后来把这个改成选做,只需要用论文的元数据做,但实际上这个做出来的效果并不好.
给分很迷,实验完全没有反馈. 我每个实验的拓展都选了两个做,最后kaggle比赛的排名也不低,最后总评却不是很好.